File connectedness?
Completed
How does this feature work? I don't understand the logic...oftentimes, the files it displays don't appear to be related to the file I'm looking at.
-

It uses a statistical measure of similarity based on the words used in the documents. It's by no means perfect -- that would require a more advanced indexing algorithm (which is not the goal of nvUltra). But it is something we essentially get "for free" with the current indexing algorithm, and can be useful when brainstorming and searching for related files in a large folder.
The list is sorted by similarity, so the lower down the list you go, the less similar the documents are. There is a relatively high threshold for excluding files altogether, so it gets noisier the lower you go.
The best results will usually be obtained when you have a folder filled with a large number of documents with a wide range of variety in the type and content of notes. For example, I have a folder consisting of approximately 1000 notes. Some are quick notes to myself. Some are long documents. Some are computer related. An example of where this works well is if I choose one of the files containing a recipe, using the connections functionality quickly shows me a list consisting of almost exclusively recipes at the top, even though the recipes are all very different from each other (different ingredients, etc)
In a smaller folder (e.g. 5-10 text documents), the results are less likely to be useful since the noise might outweigh the signal.
Depending on how valuable this feature is thought to be, I might dig into further methods to improve the results, but more out of intellectual curiosity than anything else.
0 -

Any news on this? Now, when there are Wiki Links I was expecting to see them to be the most important sorting factor, but it seems it is not true. Here is an example: I created nine _empty_ notes and added a wiki link to each other (1.md is referring 2.md, 2.md is referring 3.md, 3.md is referring 4.md etc). There are some other notes in the folder, but they are empty as well.
I was hoping to see notes to be sorted in 'connectedness' view like this:
1
2
3
4
etc
Now take a look at screenshot:
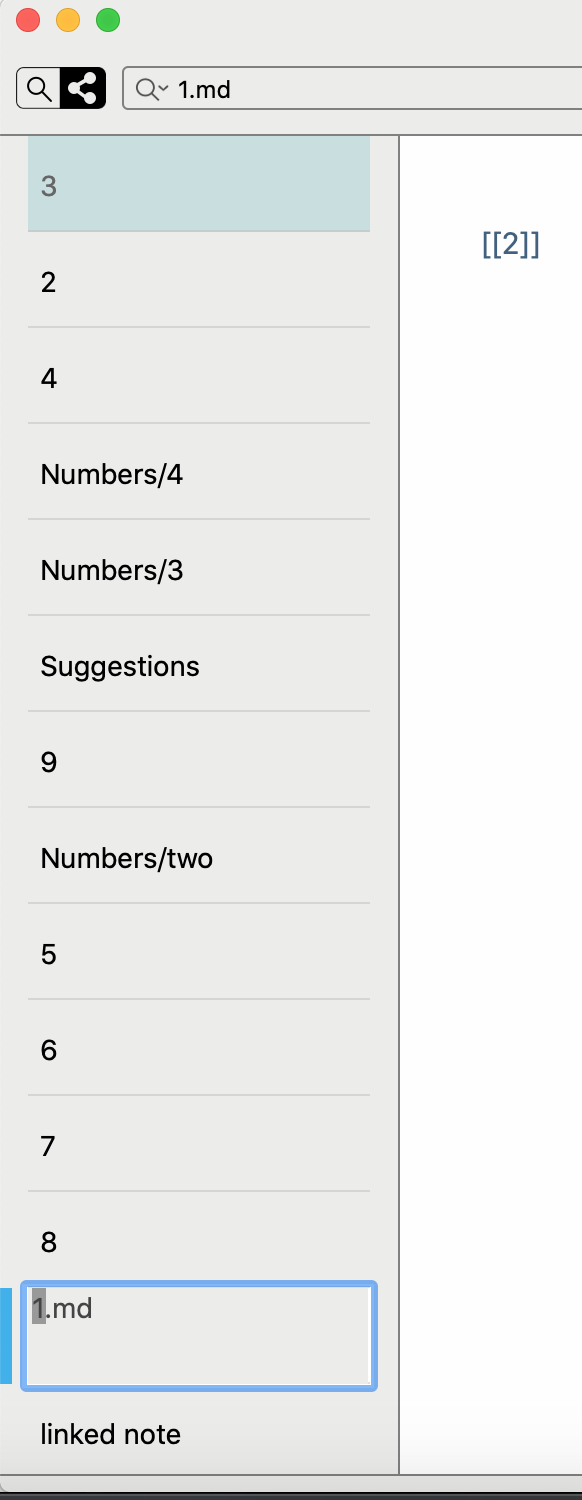
Looks wrong for me.
nvUltra Version 1.0.0 (62)
Catalina 10.15.5
0 -
Again - they are sorted based on similarity of the content. This is primarily useful when you have a **lot** of notes in a single directory that range across a wide variety of topics. For example, finding other recipes but ignoring notes about software development.
It can also be interesting when it pulls up some notes that you did not expect to be related, but in fact are in some way (e.g. as a brainstorming tool).
0 -
This might be interesting, but in the purpose of usability I strongly suggest to add direct note linking (Wiki Links) as the highest factor for sorting notes in connectedness view.
Just a quick example: I'm creating my reading list with quotes.
There is a note called 'Mark Twain' which contain wiki link to the note called 'A Connecticut Yankee in King Arthur's Court' with the quotes. And, say, there is another note somewhere, that have something like 'Best markdown practice' inside it.
Now, when selecting 'Mark Twain' note and entering the connectedness view I want to be sure the 'A Connecticut Yankee in King Arthur's Court' will be the second in sorted list - just because it is implicitly linked. And I _really_ don't want the note about markdown to break the sorting logic.
Make sense?
0 -
I understand what you're saying, but that's not what this feature is for.
0 -

Fletcher, I recently got the beta from Brett and I am working my way through both the software features and the community notes so that I don't clutter this forum with stuff already talked through. I'm a long time NV > nvAlt user (daily user, ~4000 notes).
I'd like to chime in on Valery's comment here. I think I see what you are doing with this Connected Files feature, and I really like it, finding statistically similar notes and displaying in descending order. In the same manner with the text in the full notes, is it possible to do the same thing for the text inside the brackets of [[linked notes]]?
That is, do the same Connectedness magic, but restrict it to the text in wiki link brackets, such that files that have similar text inside brackets show higher in the list. So, per your example, when searching for recipe, files with [[chicken recipes]] in them will rank higher than files with chicken and recipe.
Another example: I have summary notes for years: #2013.md and #2019.md. If I search for 2013, I would want files that have [[#2013]] in them to rank higher than files with #2013, which in turn should rank higher than files with just 2013 in them. As it is now, I believe the brackets get stripped off.
0 -
After reading a bit more, I see that I misstated my premise, because Connectedness does not depend on searching text in the search bar, but rather comparing the entire current note and looking for similar notes.
So, what I mean to say is that if the current note has [[linked notes]] inside it, then other notes that have the same (or similar) [[linked notes]] would be matched higher. So [[chicken recipes]] in both notes would be a stronger match than just chicken recipes or than recipes for chicken.
0 -
Steve Daviss -- thanks for the suggestion. But without a completely new algorithm for this, the connectedness feature works as is. It compares the complete index of the selected file with the index for each other file. It is a measure of similarity of the "words" contained in the documents, but not of the structure of the documents.
This feature is basically "free" based on the way I index documents, so it is included. At this time, we have no plans to rewrite the functionality as it would take a fair amount of effort for relatively little ROI.
0 -
Sure, I get that. Though wouldn't be much change to the algorithm, in my mind (things are always easier there :-). Simplest way might be to just count words in [[brackets]] more than the same words not in brackets. So, if one instance of brackets in the text is equal to, say, one point (in the algorithm), then one instance inside [[brackets]] is equal to, say, three points. If you've linked to them, then they have greater salience, one would expect.
The other way could be to use the same algorithm you use now for all the words in a note, but run it separately just for all the linked bracketed words across notes, and somehow merge these results with the standard results. But that is more work and, as you say, low ROI. The first way may get you closer with minimal effort.
Anyway, just adding these thoughts here in case you ever come back to the notion. Thanks.
0 -
Steve Daviss -- yep. It's a lot easier when you have no idea what you're talking about. ;) (I find myself in that situation frequently myself...)
The indexing and connectedness works nothing like that. It's about the same as if you had suggested changing the way that bracketed words "smell" as compared to unbracketed words.... :)
I am definitely open to constructive suggestions for other approaches to indexing subject to a variety of constraints that have been detailed elsewhere. A good first-level filter for whether there is a new good idea is whether the suggester can point me to the relevant article in a computer science journal or the like.
Unrelated note -- saw in your bio that you're a physician. What specialty? I'm an academic adult hospitalist.
0
Please sign in to leave a comment.
Comments
10 comments